Unsupervised Learning in Finance
What is unsupervised learning?

As the name suggests, ‘unsupervised’ learning takes place when there is no supervisor or teacher and the learner learns on her own.
For instance, consider a child who sees and tastes an apple for the very first time. She registers the colour, the texture, the taste and the smell of the fruit. The next time she sees an apple, she knows that both this and the previous apple are similar objects as they have very similar characteristics.
She knows that this is very different from an orange. But still, she does not know what it is called in human-speak, i.e. an ‘apple’ as there is no knowledge of the label.
Such learning where the labels do not exist (in the absence of a teacher) but the learner can still learn about patterns on her own is referred to as unsupervised learning.
In the context of machine learning algorithms, unsupervised learning occurs when an algorithm learns from plain examples without any associated response and determines the data patterns on its own.
In the next section, we will discuss how this type of learning differs from the other type of popular learning algorithms in machine learning, i.e. supervised learning algorithms.
Supervised vs unsupervised learning
Learning in supervised learning, as the name suggests, occurs under supervision, i.e., when the algorithm predicts a value for a sample from the training data, it is told whether the prediction was correct or not.
This is possible as we have the correct values stored as ‘labels’/’target variable’, which are passed to the algorithm along with the input data. Common supervised learning tasks are those of classification and regression.
In classification tasks, the labels are the correct class to which the sample belongs, whereas, in regression, the actual value of the dependent variable(Y) serves as a benchmark for comparing the prediction. The algorithm can then tweak its parameters to achieve higher accuracy in prediction.
Thus, the main goal of supervised learning is to build a robust predictive model.
On the other hand, in unsupervised learning, we only pass the input data, and there are no labels. Unsupervised models seek to find the underlying or hidden structure or distribution in the data in order to learn more about the data.
In other words, unsupervised learning is where we only have input data and no corresponding output variables, and the main goal is to learn more or discover new insights from the input data itself.
A common example of unsupervised algorithms are the clustering algorithms, that group the data based on the patterns that the machine detects.
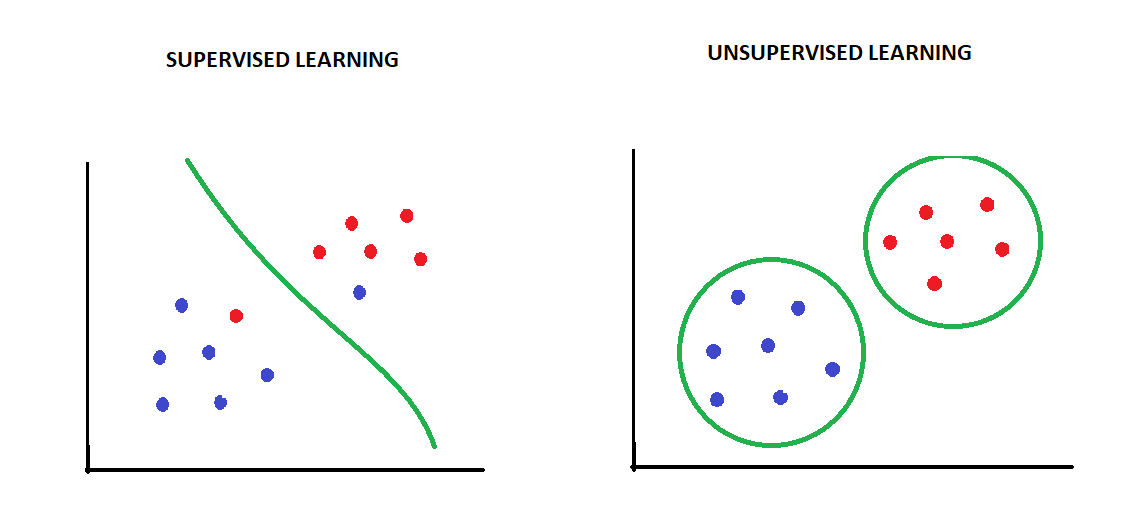
For example, let us consider a situation in which we have a few data points based on two input features X1 and X2.
- If we want our algorithm to classify/categorize the data into two known classes, we will use a supervised classification algorithm.
- On the other hand, if we want the algorithm to tell us how the data is structured, we would use an unsupervised clustering algorithm.